주식의 차트들을 보면, 기본 정보인 분봉이외에 여러 값들이 있습니다.
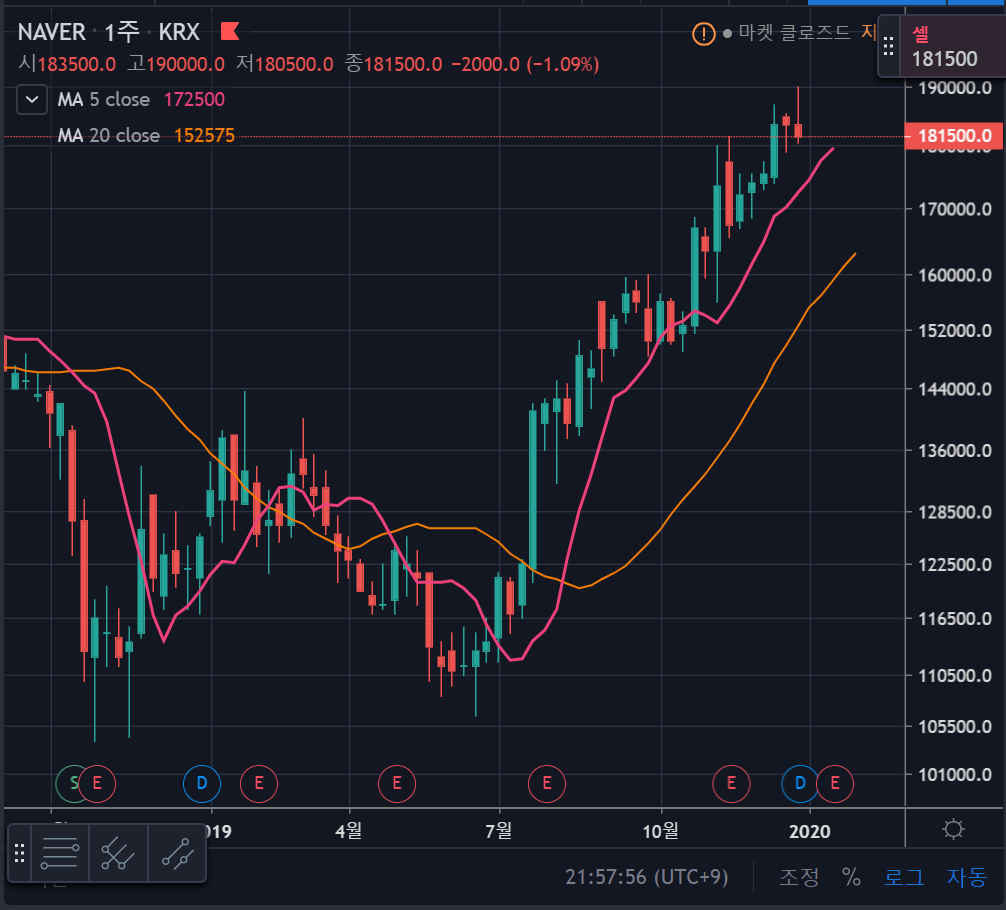
위의 사진은 트레이딩 뷰(https://kr.tradingview.com/chart/m9TGPsC1/) 라는 차트 전문 사이트에서 갖고 온 차트입니다.
캔들로 이루어진 분봉 이외에 선으로 그어져 있는데, 각각 MA (Move Average) 5, 20 즉 평균 이평선 5, 20일선 입니다.
그런데 전에 크롤링 해온 데이터는 기본값 (시간, 시가, 고가, 저가, 종가, 거래량) 뿐이고, 그 이외의 지표들은 각각 계산해야 합니다.
계산식이야 하기와 같은 공식 설명 및 엑셀 구현 을 찾아보면서, 파이썬으로 수식을 옮겨도 되지만
여기서 버그가 나기라도 하면 (물론 식을 완성하고 검증해서 엑셀 출력 결과물과 맞는지 확인 해야겠죠!)
문제가 많고...
https://school.stockcharts.com/doku.php?id=technical_indicators:moving_averages
Moving Averages - Simple and Exponential [ChartSchool]
Moving Averages - Simple and Exponential Introduction Moving averages smooth the price data to form a trend following indicator. They do not predict price direction, but rather define the current direction, though they lag due to being based on past prices
school.stockcharts.com
무엇보다 이런 바퀴 만드는 작업을 다른 사람들이라고 똑같이 안했을리가 없습니다.
그래서 누군가 이런 라이브러리 만들어서 공개해놓은게 있는데, 그것이 TA-Lib(Technical Analysis Library) 입니다.
아래에서 여러 공식을 뽑아내는 함수를 확인 할 수 있습니다.
https://ta-lib.org/function.html
Function List
ta-lib.org
파이썬으로 와핑한 라이브러리가 있는데 아래에서 확인 할 수 있습니다.
https://github.com/mrjbq7/ta-lib
mrjbq7/ta-lib
Python wrapper for TA-Lib (http://ta-lib.org/). Contribute to mrjbq7/ta-lib development by creating an account on GitHub.
github.com
이제 이 talib를 사용해서 주식 데이터를 관리할 클래스를 만들어 보겠습니다.
calcIndicator 함수를 주목해 주세요
<StockData.py>
# pip install ta-lib
#
# OR 실패시 라이브러리 다운받아서 직접 해보기
# pip install .\TA_Lib-0.4.17-cp37-cp37m-win_amd64.whl
#
# OR
# 아나콘다를 사용해서 인스톨 방법
# conda install -c quantopian ta-lib
# conda install -c masdeseiscaracteres ta-lib
# conda install -c developer ta-lib
from enum import Enum
import os
import talib
import talib.abstract as ta
from talib import MA_Type
import dataframe
import pandas as pd
import numpy as np
class BuyState (Enum):
없음 = 0
매수 = 1
class stockData:
buyCount_ = 0
buyPrice_ = 0
position_ = BuyState.없음
def __init__(self, code, name, dataFrame):
self.code_ = code
self.name_ = name
self.indicators_ = dataFrame
# 지금 캔들(갱신될 수 있음)
def candle0(self):
rowCnt = self.indicators_.shape[0]
if rowCnt == 0:
return None
return self.indicators_.iloc[-1]
# 완전히 완성된 캔들 (고정된 가장 최신 캔들)
def candle1(self):
rowCnt = self.indicators_.shape[0]
if rowCnt < 1:
return None
return self.indicators_.iloc[-2]
# 완성된 캔들의 직전 캔들 (지표간 cross 등 판단을 위함.)
def candle2(self):
rowCnt = self.indicators_.shape[0]
if rowCnt < 2:
return None
return self.indicators_.iloc[-3]
def calcProfit(self):
if self.buyCount_ == 0:
return 0
profit = self.buyCount_ * self.buyPrice_
return profit
# 각종 보조지표, 기술지표 계산
def calcIndicator(self):
arrClose = np.asarray(self.indicators_["close"], dtype='f8')
arrHigh = np.asarray(self.indicators_["high"], dtype='f8')
arrLow = np.asarray(self.indicators_["low"], dtype='f8')
# 이평선 계산
self.indicators_["sma5"] = ta._ta_lib.SMA(arrClose, 5)
self.indicators_["sma10"] = ta._ta_lib.SMA(arrClose, 10)
self.indicators_["sma20"] = ta._ta_lib.SMA(arrClose, 20)
self.indicators_["sma50"] = ta._ta_lib.SMA(arrClose, 50)
self.indicators_["sma100"] = ta._ta_lib.SMA(arrClose, 100)
self.indicators_["sma200"] = ta._ta_lib.SMA(arrClose, 200)
self.indicators_["ema5"] = ta._ta_lib.EMA(arrClose, 5)
self.indicators_["ema10"] = ta._ta_lib.EMA(arrClose, 10)
self.indicators_["ema20"] = ta._ta_lib.EMA(arrClose, 20)
self.indicators_["ema50"] = ta._ta_lib.EMA(arrClose, 50)
self.indicators_["ema100"] = ta._ta_lib.EMA(arrClose, 100)
self.indicators_["ema200"] = ta._ta_lib.EMA(arrClose, 200)
self.indicators_["wma5"] = ta._ta_lib.WMA(arrClose, 5)
self.indicators_["wma10"] = ta._ta_lib.WMA(arrClose, 10)
self.indicators_["wma20"] = ta._ta_lib.WMA(arrClose, 20)
self.indicators_["wma50"] = ta._ta_lib.WMA(arrClose, 50)
self.indicators_["wma100"] = ta._ta_lib.WMA(arrClose, 100)
self.indicators_["wma200"] = ta._ta_lib.WMA(arrClose, 200)
#볼린저 계산
upper, middle, low = ta._ta_lib.BBANDS(arrClose, 20, 2, 2, matype=MA_Type.SMA)
self.indicators_["bbandUp"] = upper
self.indicators_["bbandMid"] = middle
self.indicators_["bbandLow"] = low
# 기타 자주 사용되는 것들
self.indicators_["rsi"] = ta._ta_lib.RSI(arrClose, 14)
self.indicators_["cci"] = ta._ta_lib.CCI(arrHigh, arrLow, arrClose, 14)
self.indicators_["williumR"] = ta._ta_lib.WILLR(arrHigh, arrLow, arrClose, 14)
self.indicators_["parabol"] = ta._ta_lib.VAR(arrClose, 5, 1)
self.indicators_["adx"] = ta._ta_lib.ADX(arrHigh, arrLow, arrClose, 14)
self.indicators_["plusDI"] = ta._ta_lib.PLUS_DI(arrHigh, arrLow, arrClose, 14)
self.indicators_["plusDM"] = ta._ta_lib.PLUS_DM(arrHigh, arrLow, 14)
self.indicators_["atr"] = ta._ta_lib.ATR(arrHigh, arrLow, arrClose, 30)
이제 제대로 계산되는지 확인해 봅시다.
<main.py>
### 먼저 설치할것들
# python -m pip install --upgrade pip
# conda update -n base conda
# conda update --all
# pip install pandas
# pip install pandas-datareader
# pip install dataframe
import pandas as pd
import dataframe
import sqlite3
import datetime
import WebStockDataGetter
import SqliteStockDB
import StockData
import MachineLearningPredic
import StockPredic
# 메인 함수 시작
if __name__ == '__main__':
# 네이버 데이터 크롤러
getter = WebStockDataGetter.naverGetter()
stockDf = getter.getKoreaStocksFromFile()
# Sqlite에 데이터 저장
dayPriceDB = SqliteStockDB.dayPriceDB('KoreaStockData.db')
totalCount = len(stockDf)
stockPool = {}
# 주식의 일자데이터 크롤링 / db 에서 갖고 오기
for idxi, rowCode in stockDf.iterrows():
code = rowCode['code']
name = rowCode['name']
maxGetPage = 3
# DB에 데이터가 없으면 테이블을 만듬
tableName = dayPriceDB.tableName(code)
if dayPriceDB.checkTable(tableName) == False:
if dayPriceDB.createTable(tableName) == False:
continue
else:
maxGetPage = 100
# 크롤러에게 code 넘기고 넷 데이터 긁어오기
df = getter.crawlingNaverStockInfo(code, maxGetPage)
if df is None:
print("! 주식 [%s] 의 크롤링 실패" % (name))
continue
data = pd.DataFrame(df, columns=['날짜', '시가', '고가', '저가', '종가', '거래량'])
# 데이터 저장
dayPriceDB.save(tableName, data)
print("====== 주식 일봉 데이터 [%s] 저장 완료 (%d/%d) =====" % (name, idxi, totalCount))
# db에 저장 시킨 값을 다시 갖고오지 (검증!)
df = dayPriceDB.load(tableName)
if df is None:
continue
# stockData 만들어서 pool에 담기
sd = StockData.stockData(code, name, df)
stockPool[name] = sd
# 기술지표 계산
sd.calcIndicator()
print("--- [%s]" % sd.name_)
print(sd.indicators_)
# 주식데이터 각각을 백테스팅
for name, sd in stockPool.items():
candle = sd.candle0()
print( "# 주식 [%s]의 [%s] 종가 [%d]" % (name, candle['candleTime'], candle['close']))
# 여러 전략들을 조합해서 구매에 적합한 전략을 찾기
# 괜찮은 매매 타이밍 sort 해서 텔레그램으로 전송
print(sd.indicators_) 를 통해 아래와 같이 이평선, rsi, cci 등 여러 보조 지표들이 한번에 계산되는걸 확인 할 수 있습니다.
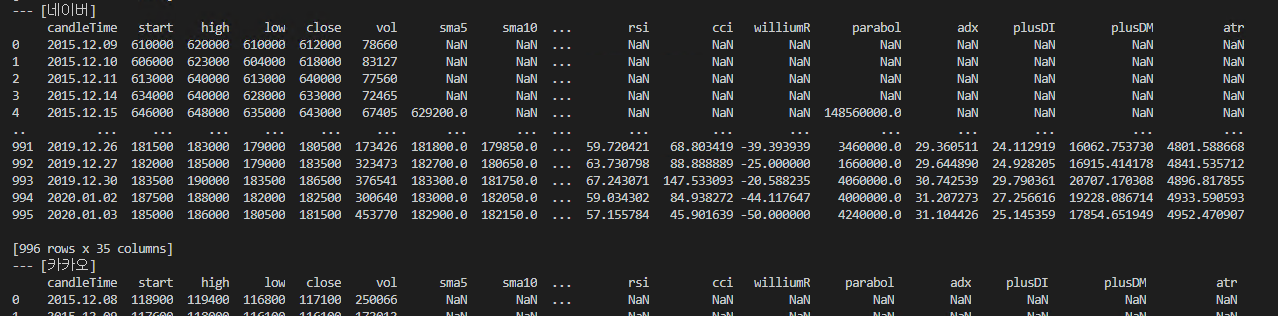
추가로 그 이외의 소스 파일들도 소소하게 변경 되었으니 아래의 크롤러와 db 쪽 소스 파일도 바꿔 줍니다.
<SqliteStockDB.py>
import pandas as pd
import dataframe
import sqlite3
import datetime
class dayPriceDB:
# DB 폴더가 준비 되어 있어여함.
def __init__(self, dbName):
self.conn_ = sqlite3.connect('./DB/' + dbName)
def tableName(self, code):
name = "DayPriceTable_" + code
return name
# 테이블 이름이 있는지 확인
def checkTable(self, tableName):
with self.conn_:
cur = self.conn_.cursor()
sql = "SELECT count(*) FROM sqlite_master WHERE Name = \'%s\'" % tableName
cur.execute(sql)
rows = cur.fetchall()
for row in rows:
if str(row[0]) == "1":
return True
return False
# 테이블 생성
def createTable(self, tableName):
with self.conn_:
try:
cur = self.conn_.cursor()
sql = "CREATE TABLE %s (candleTime DATETIME PRIMARY KEY, start INT, high INT, low INT, close INT, vol INT);" % tableName
cur.execute(sql)
return True
except:
log = "! [%s] table make fail" % tableName
print(log)
return False
# 데이터 저장
def save(self, tableName, dataframe):
with self.conn_:
try:
cur = self.conn_.cursor()
sql = "INSERT OR REPLACE INTO \'%s\'" % tableName
sql = sql + " ('candleTime', 'start', 'high', 'low', 'close', 'vol') VALUES(?, ?, ?, ?, ?, ?)"
cur.executemany(sql, dataframe.values)
self.conn_.commit()
except:
return None
# 데이터 로드
def load(self, tableName):
with self.conn_:
try:
sql = "SELECT candleTime, start, high, low, close, vol FROM \'%s\' ORDER BY candleTime ASC" % tableName
df = pd.read_sql(sql, self.conn_, index_col=None)
return df
except:
return None
<WebStockDataGetter.py>
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import dataframe
import sqlite3
import datetime
from datetime import datetime
class naverGetter:
def getKoreaStocksFromWeb(self):
# 한국 주식 회사 등록 정보 가지고 오기
stockDf = pd.read_html('http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13', header=0)[0]
stockDf.종목코드 = stockDf.종목코드.map('{:06d}'.format)
stockDf = stockDf[['회사명', '종목코드']]
stockDf = stockDf.rename(columns={'회사명': 'name', '종목코드': 'code'})
return stockDf
def getKoreaStocksFromFile(self):
with open("./targetList.txt", "r", encoding="utf-8") as f:
targetList = f.read().splitlines()
stockDf = DataFrame(columns = ("name", "code"))
for text in targetList:
tokens = text.split(':')
row = DataFrame(data=[tokens], columns=["name", "code"])
stockDf = stockDf.append(row)
stockDf = stockDf.reset_index(drop=True)
return stockDf
def __getNaverURLCode(self, code):
url = 'http://finance.naver.com/item/sise_day.nhn?code={code}'.format(code=code)
print("요청 URL = {}".format(url))
return url
# 종목 이름을 입력하면 종목에 해당하는 코드를 불러와
def getNaverStockURL(self, item_name, stockDf):
code = stockDf.query("name=='{}'".format(item_name))['code'].to_string(index=False)
url = self.__getNaverURLCode(code)
return url
def crawlingNaverStockInfo(self, code, maxGetPage):
# 일자 데이터를 담을 df라는 DataFrame 정의
df = pd.DataFrame()
try:
url = self.__getNaverURLCode(code)
# 1페이지가 10일. 100페이지 = 1000일 데이터만 가져오기
for page in range(1, int(maxGetPage)):
pageURL = '{url}&page={page}'.format(url=url, page=page)
df = df.append(pd.read_html(pageURL, header=0)[0], ignore_index=True)
# df.dropna()를 이용해 결측값 있는 행 제거
df = df.dropna()
#print(df)
return df
except:
return None
위에 보면 getKoreaStocksFromFile 함수에 하드코딩으로 targetList.txt 파일을 불러오고 있습니다.
이 리스트는 [종목명]:[종목코드] 로 구성되어 있고 저는 아래와 같은 주식 / ETF / ETN 에 대해서만 할 예정입니다.
<targetList.txt>
삼성전자:005930
SK하이닉스:000660
네이버:035420
카카오:035720
현대차:005380
호텔신라:008770
삼성SDI:006400
LG화학:051910
KODEX 코스닥150 레버리지:233740
KODEX 200선물인버스2X:252670
KODEX 레버리지:122630
KODEX 코스닥150선물인버스:251340
KODEX 인버스:114800
KODEX 코스닥 150:229200
KODEX 200:069500
TIGER 200선물인버스2X:252710
TIGER 200:102110
TIGER 코스닥150 레버리지:233160
신한 레버리지 천연가스 선물 ETN(H):500031
신한 인버스 2X WTI원유 선물 ETN(H):500027
삼성 레버리지 천연가스 선물 ETN:530037
삼성 KTOP30 ETN:530013
삼성 인버스 2X WTI원유 선물 ETN:530036
신한 인버스 2X 다우존스지수 선물 ETN(H):500028
신한 레버리지 은 선물 ETN(H):500029'재테크' 카테고리의 다른 글
| 집에서 비트코인이나 도지코인 채굴 하기 (0) | 2021.04.19 |
|---|---|
| 일부 종목만 선택해서 데이터 갖고 오기 (1) | 2019.12.18 |
| 파이썬으로 네이버 주식의 데이터 긁어 오기 (0) | 2019.12.15 |
| 시스템 트레이딩을 하기 위해 필요한 것들 (0) | 2019.12.15 |
| 시스템 트레이딩 시작하며 (0) | 2019.12.15 |













![[해외] 테크닉 Enzo Ferrari (1359pcs) 레고호환블록](https://static.coupangcdn.com/image/affiliate/banner/3b63cd7db523a850c1bf73c7673cb0c7@2x.jpg)