FAANG 주식은 승승장구니 뭐니 미국 주식에 대한 많은 이야기가 들립니다. (대부분 글로벌을 상대하는 회사들)
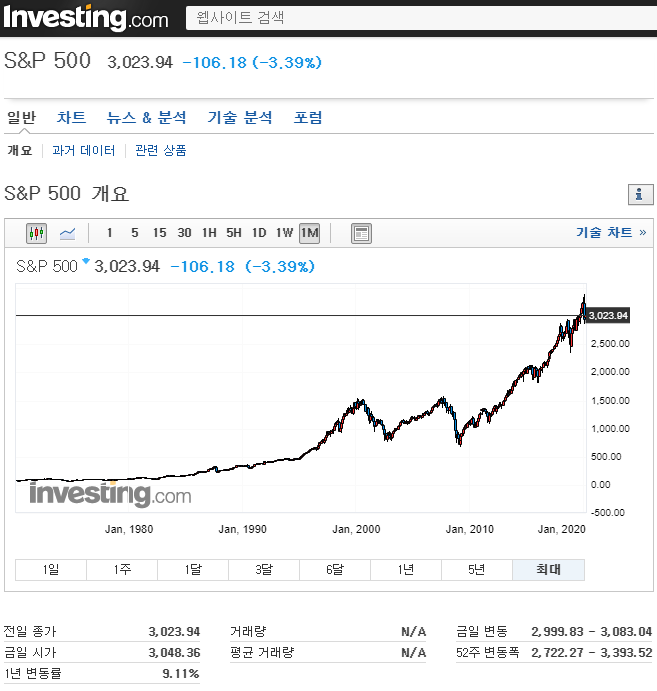
실제로 미국 주식을 보면 확실한 우상향을 이루고 있습니다.
주식 책에 자주 보이는 장기 투자를 하게 되면 먹는 시장이니,
안목을 보고 좋은 주식을 골라야 하니, 이건 모두 미국 주식에 대한 이야기라고 볼 수 있겠죠. (왜냐면 우상향)
Tesla's stock recently skyrocketed, Microsoft's market cap exceeded 1,000 trillion, FAANG stocks are a winning game, and there are many stories about US stocks. (Most global companies)
In fact, looking at U.S. stocks, there is a clear upside. The long-term investments often seen in stock books are beneficial, so you have to look at your eyes and pick good stocks, so this is all about American stocks. (Because it's upward)
반면 한국 주식을 보면 박스권에 갇혀있다란 이야기를 많이 들으셨을 껍니다.
물론 우상향을 보이기는 하지만, 최근 10년을 보면 미국주식은 달려 나가는데, 한국 지수는 2000에서 벗어나지 못하고 있죠.
On the other hand, if you look at Korean stocks, you may have heard a lot about being trapped in a box. Of course, it shows an upward trend, but in the last 10 years, US stocks are running out, but the Korean index has not escaped 2000.
그래서 최근에 한국 주식에 염증을 느끼고, 미국 주식으로 들어가는 사람들이 많아지고 있습니다.
정부도 그렇기 때문에 외화반출 이유를 들어서 이익금의 22%를 양도세율을 올렸습니다. (250만원까지는 공제) 전에는 양도세율이 10% 였을껍니다 ㅠㅠ..
So, recently, Korean stocks are inflamed, and more and more people are entering into US stocks. The government is also doing so, raising the transfer tax rate of 22% of the profits for reasons of foreign currency export. (Deduction up to 2.5 million won) Transfer tax rate would have been 10% before.
어쨋든 저도 처음엔 한국 주식을 좀 하다가 이게 잘 안되서
요즘 미국 주식을 보고 있습니다. 그리고 신중하게 일개 저같은 사람이 알 정도의 회사라면, 전세계적으로 장사를 하는거니 망하지 않고 장기투자시 어쨋든 오르는 주식이 아닐까 생각합니다.
Anyway, I did some Korean stock at first, but this didn't work I'm looking at US stocks these days. And, carefully, if a company like me knows enough, I think that it is a stock that rises in the long-term investment without ruin because it is a business worldwide. (Amazon, Google, Apple, Facebook, Netflix, Microsoft, Tesla, Visa, Starbucks, JP Morgan, AMD, NVIDA, Disney, Costco, etc.)
미국 주식은 종목수만 5000여개가 넘습니다. 이 많은 주식중에 어떤게 아직 발굴되지 않은 옥석인지 확인하는건 언어 장벽도 있고 어려움이 많죠.
그래서 앱을 하나 만들었습니다.
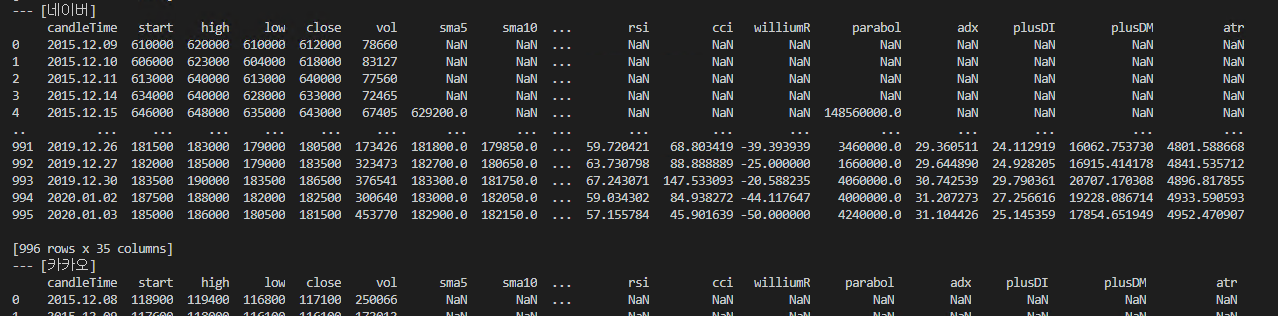
나스닥 100에 등록된 대표 종목과, S&P500 의 500 개 종목에 대해서 머신러닝 예측을 써서 다음날 주식 가격 예측을 통해 추세를 판단 할 수 있는 앱입니다.
There are more than 5000 stocks in the United States. There are language barriers and difficulties in identifying which of these stocks is an unexplored boulder.
So I created an app. It is an app that can determine the trend through the stock price prediction of the next day by writing machine learning forecasts for the 500 stocks of S & P 500 and the representative stocks registered in the NASDAQ 100.
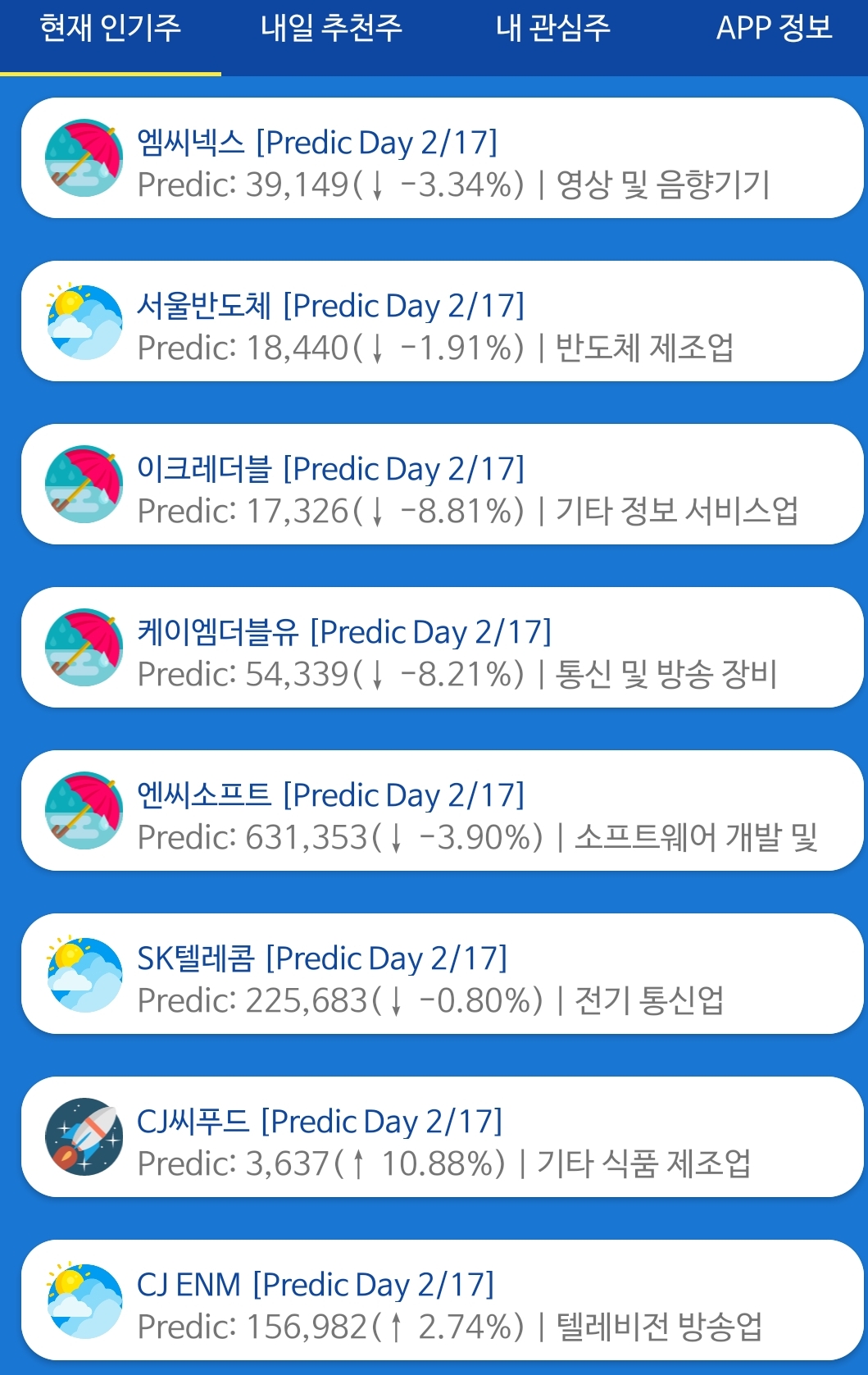
이건 야후 파이넨셜에서 미국 사람들이 최근 많이 보는 Trend ticker 페이지의 목록을 불러 왔습니다.
When you install the app, the following list appears. 1. Web trend This brings up a list of Trend ticker pages that Americans see a lot recently.
목록을 클릭하면 그 주식의 예측가격이 나옵니다.
Click on the list to get the forecast price of the stock.
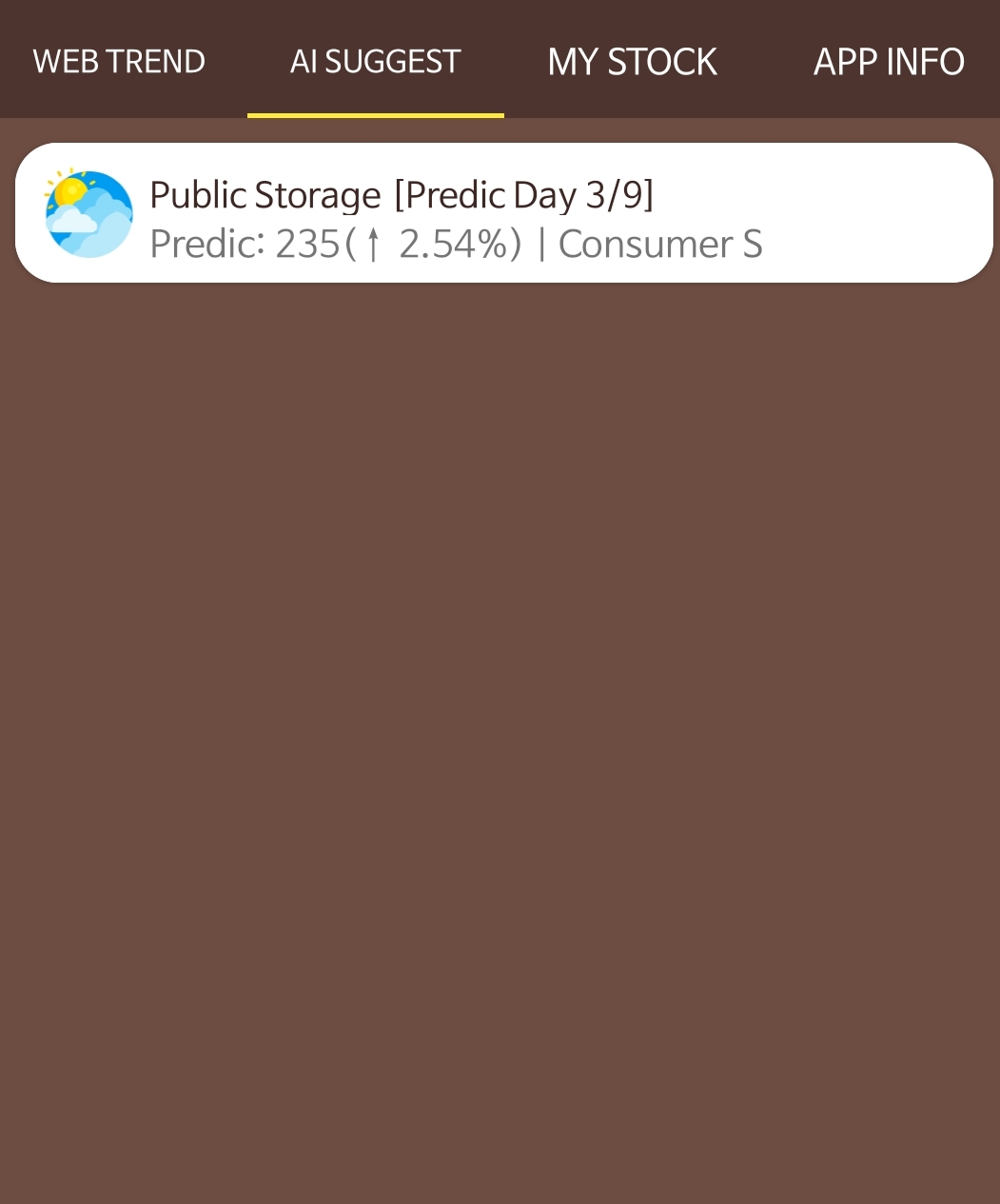
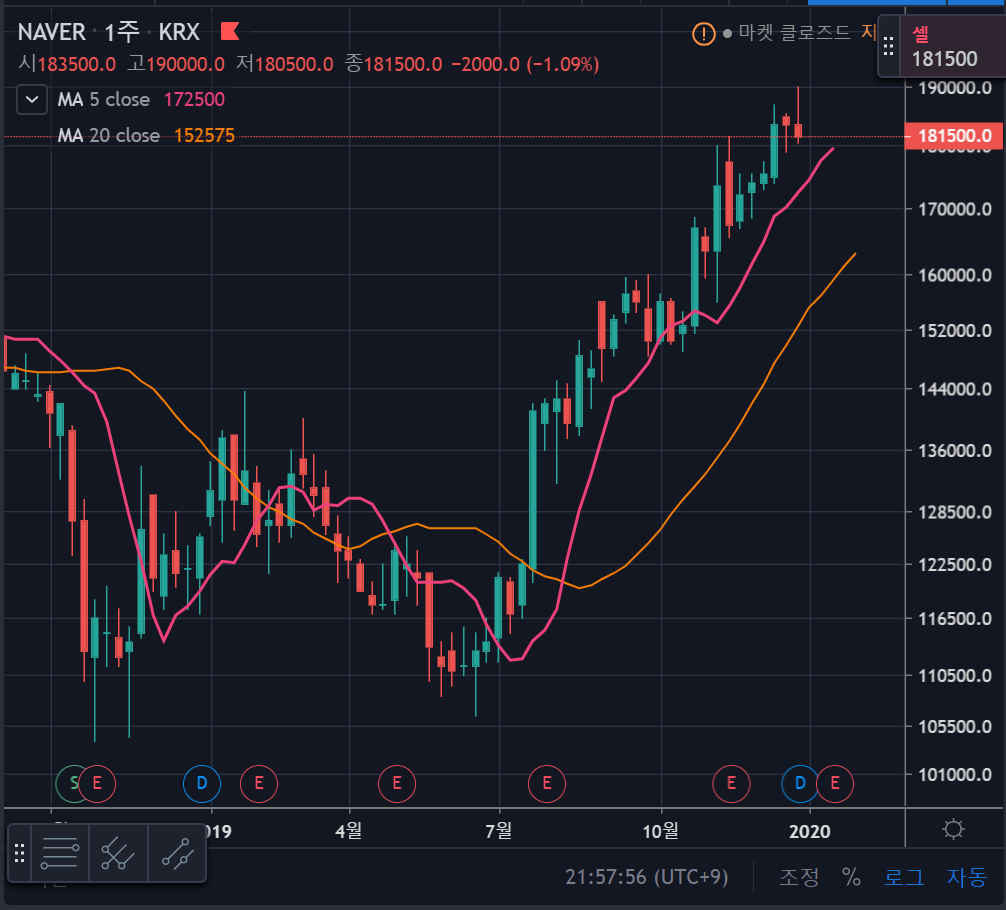
2. 추천 주식은 예측 값이 상승이고, ema 차트상 골든 크로스 된 주식의 목록을 출력합니다.
오늘은 퍼블릭 스토리지 이거 하나만 있군요.
2. Recommended stocks have a higher forecast value, and output a list of stocks with golden crosses on the ema chart. Today there is only one public storage.
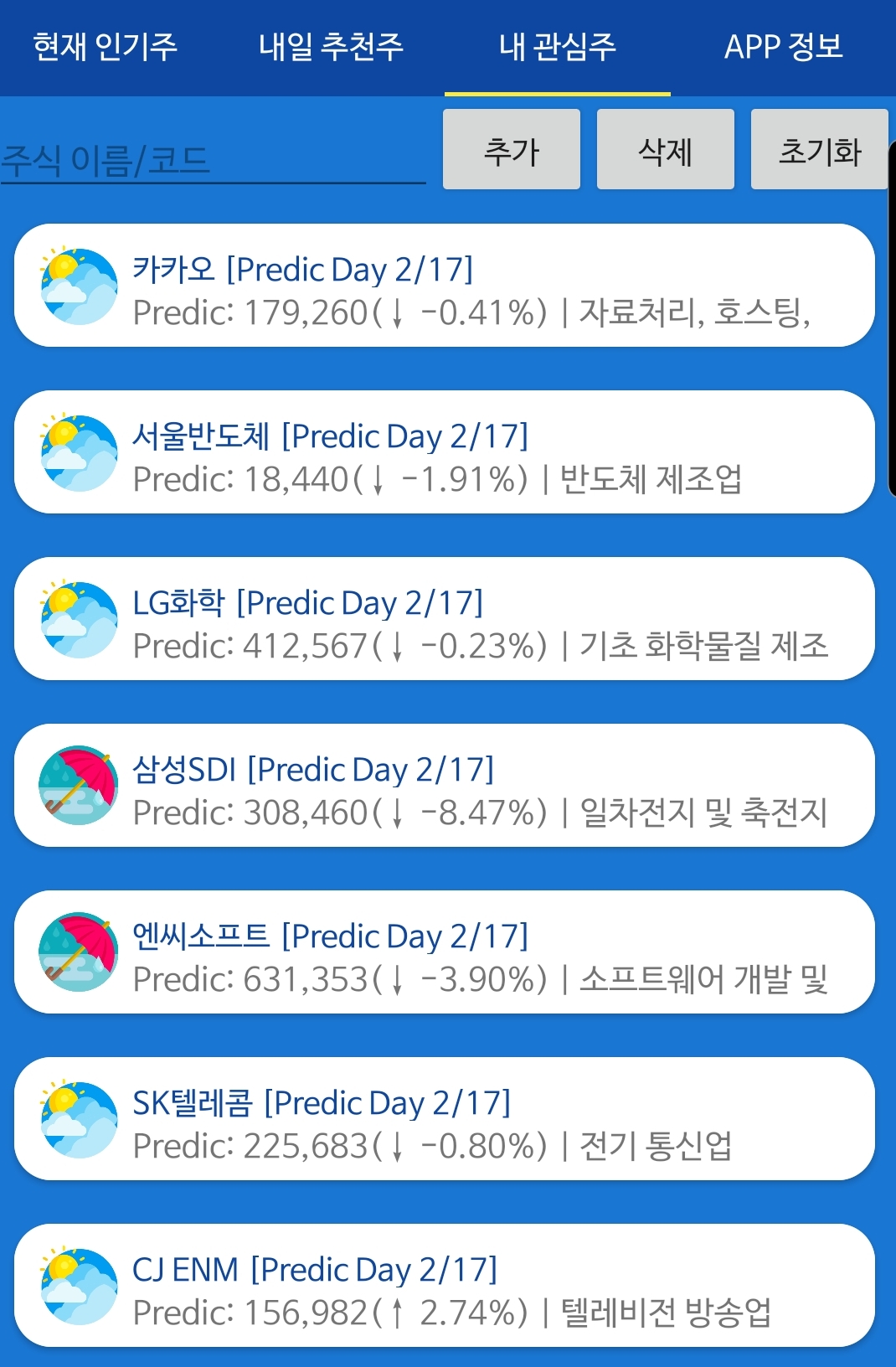
3. my stock 은 원하는 목록에 대해서 예측값을 볼 수 있습니다.
입력은 Ticker 라고 하는 코드명을 입력해 주셔야 합니다. APPLE = (AAPL)
3. my stock allows you to see the predictions for the desired list. You must enter the code name Ticker. APPLE = (AAPL)
미국 주식 투자를 함에 있어서 여러 도움이 되었으면 합니다.
I hope this will help you in investing in US stocks.






























![[해외] 테크닉 Enzo Ferrari (1359pcs) 레고호환블록](https://static.coupangcdn.com/image/affiliate/banner/3b63cd7db523a850c1bf73c7673cb0c7@2x.jpg)