출처 : http://www.webmadang.net/database/database.do?action=read&boardid=4001&page=null&seq=5
[MSSQL - GROUP BY HAVING 을 이용한 중복 데이타 체크]
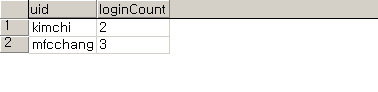
위 테이블의 레코드를 보면 mfcchang이라는 uid가 3회나 로그인 했다는 것을 알 수 있습니다. 레코드의 갯수가 작아서
위와 같은 쿼리를 실행해보면 GROUP BY 에 의해서 uid 컬럼의 count가 집계되고 결과는 아래와 같습니다.
출력해 보면 결과는 아래와 같습니다. 아래의 결과에서 두번 즉 2회 이상 로그인한 사람은 kimchi 와 mfcchang 이라는 uid의 소유자 뿐임을 알수 있습니다.
하나의 테이블을 사용할때와 틀린부분은 UNION ALL 로 해당 테이블을 묶어서 서브쿼리로 처리한다는 것뿐입니다.
|




'DataBase' 카테고리의 다른 글
| XQuery를 사용한 XML 데이터 업데이트 (0) | 2013.09.17 |
|---|---|
| 프로시저 내 특정 단어 검색하기 (0) | 2013.09.02 |
| 실행 중인 쿼리의 처리 상태 확인 - sys.dm_exec_requests (0) | 2013.08.01 |
| MSSQL Lock 정보 확인 및 해제 (0) | 2013.08.01 |
| OpenQuery를 이용한 Select, Insert, Update, Delete Database (0) | 2013.06.18 |

