소스파일은 github.com/galaxywiz/StockCrawler_py 에서 확인 가능합니다.
이전 장에서 가지고 온 주식데이터를 담을 그릇을 만들어볼 차례입니다.
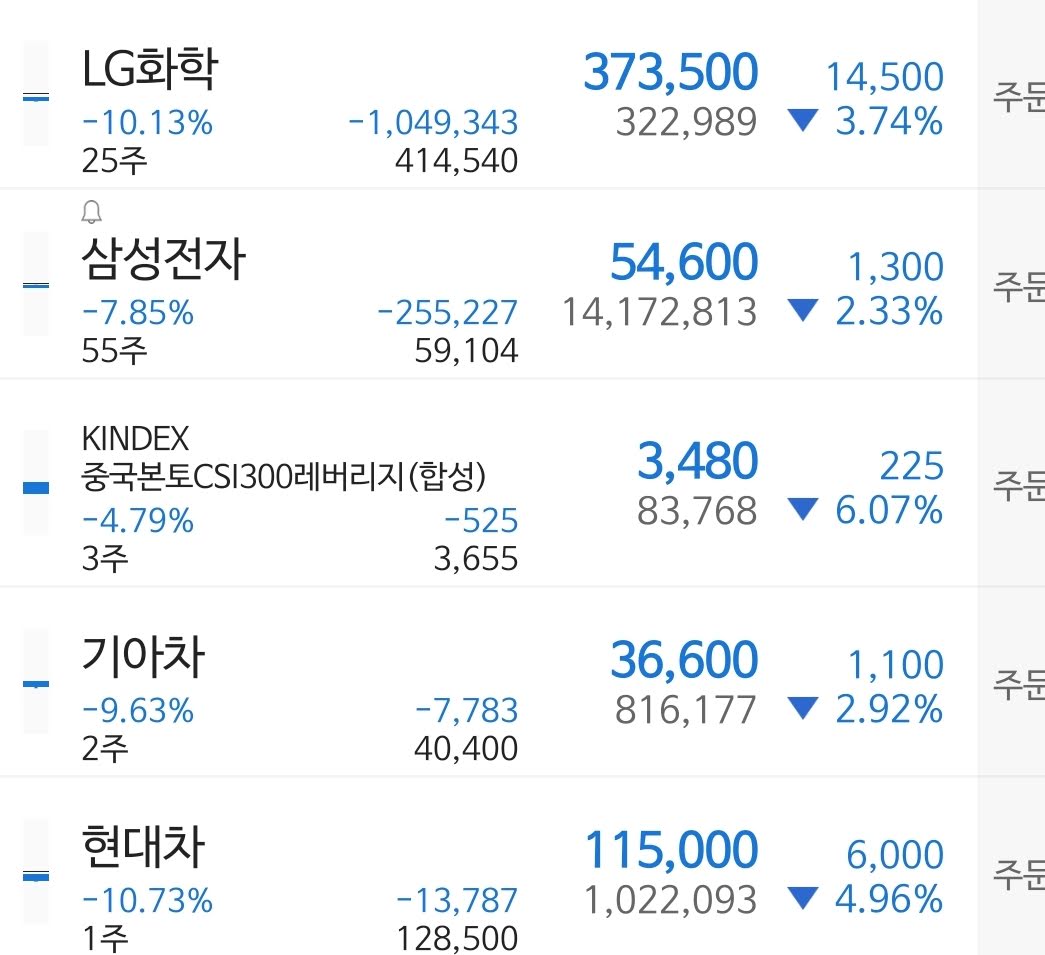
이전 장, 야후 파이낸셜이나, 네이버 금융 페이지에서 데이터를 가지고 오는데, 해당 페이지를 방문하면 오른쪽과 같은 페이지의 데이터를 가지고 온 것입니다.

이제 저 데이터들을 웹으로부터 가지고 왔으니, 이를 우리 프로그램에 맞게 사용할 수 있도록 만들어 봅니다.
저는 오른쪽과 같이 구성해보고자 합니다.

기본데이터는 웹에서 가지고 온 데이터(앞 글자 영어 따서 ohlc 데이터라 합니다), 이를 기반으로 계산한 보조 지표, 매수 정보 같은 건 추후 실제 매매 API를 붙이기 위해 만들어 두었습니다.
stockData.py
from enum import Enum
import os
import talib
import talib.abstract as ta
from talib import MA_Type
import dataframe
import pandas as pd
import numpy as np
import util
class BuyState (Enum):
STAY = 0
BUY = 1
SELL = 2
class StockData:
def __init__(self, code, name, df):
self.code_ = code
self.name_ = name
self.chartData_ = df
self.buyCount_ = 0
self.buyPrice_ = 0
self.position_ = BuyState.STAY
self.predicPrice_ = 0 # 머신러닝으로 예측한 다음날 주식값
self.strategyAction_ = BuyState.STAY
self.teleLog_ = ""
self.marketCapRanking_ = 0
def canPredic(self):
size = len(self.chartData_)
if size < 300:
return False
return True
def calcPredicRate(self):
if self.canPredic() == False:
return 0
nowPrice = self.candle0()
rate = util.calcRate(nowPrice["close"], self.predicPrice_)
return rate
# 최신 캔들
def candle0(self):
rowCnt = self.chartData_.shape[0]
if rowCnt == 0:
return None
return self.chartData_.iloc[-1]
# 전날 캔들
def candle1(self):
rowCnt = self.chartData_.shape[0]
if rowCnt <= 1:
return None
return self.chartData_.iloc[-2]
#
def candle2(self):
rowCnt = self.chartData_.shape[0]
if rowCnt <= 2:
return None
return self.chartData_.iloc[-3]
def calcProfit(self):
if self.buyCount_ == 0:
return 0
profit = self.buyCount_ * self.buyPrice_
return profit
# 각종 보조지표, 기술지표 계산
def calcIndicator(self):
arrClose = np.asarray(self.chartData_["close"], dtype='f8')
arrHigh = np.asarray(self.chartData_["high"], dtype='f8')
arrLow = np.asarray(self.chartData_["low"], dtype='f8')
# 이평선 계산
self.chartData_["sma5"] = ta._ta_lib.SMA(arrClose, 5)
self.chartData_["sma10"] = ta._ta_lib.SMA(arrClose, 10)
self.chartData_["sma20"] = ta._ta_lib.SMA(arrClose, 20)
self.chartData_["sma50"] = ta._ta_lib.SMA(arrClose, 50)
self.chartData_["sma100"] = ta._ta_lib.SMA(arrClose, 100)
self.chartData_["sma200"] = ta._ta_lib.SMA(arrClose, 200)
self.chartData_["ema5"] = ta._ta_lib.EMA(arrClose, 5)
self.chartData_["ema10"] = ta._ta_lib.EMA(arrClose, 10)
self.chartData_["ema20"] = ta._ta_lib.EMA(arrClose, 20)
self.chartData_["ema50"] = ta._ta_lib.EMA(arrClose, 50)
self.chartData_["ema100"] = ta._ta_lib.EMA(arrClose, 100)
self.chartData_["ema200"] = ta._ta_lib.EMA(arrClose, 200)
self.chartData_["wma5"] = ta._ta_lib.WMA(arrClose, 5)
self.chartData_["wma10"] = ta._ta_lib.WMA(arrClose, 10)
self.chartData_["wma20"] = ta._ta_lib.WMA(arrClose, 20)
self.chartData_["wma50"] = ta._ta_lib.WMA(arrClose, 50)
self.chartData_["wma100"] = ta._ta_lib.WMA(arrClose, 100)
self.chartData_["wma200"] = ta._ta_lib.WMA(arrClose, 200)
macd, signal, osi = ta._ta_lib.MACD(arrClose, fastperiod=12, slowperiod=26, signalperiod=9)
self.chartData_["MACD"] = macd
self.chartData_["MACDSignal"] = signal
self.chartData_["MACDOsi"] = osi
#볼린저 계산
upper, middle, low = ta._ta_lib.BBANDS(arrClose, 20, 2, 2, matype=MA_Type.SMA)
self.chartData_["bbandUp"] = upper
self.chartData_["bbandMid"] = middle
self.chartData_["bbandLow"] = low
# 기타 자주 사용되는 것들
self.chartData_["rsi"] = ta._ta_lib.RSI(arrClose, 14)
self.chartData_["cci"] = ta._ta_lib.CCI(arrHigh, arrLow, arrClose, 14)
self.chartData_["williumR"] = ta._ta_lib.WILLR(arrHigh, arrLow, arrClose, 14)
self.chartData_["parabol"] = ta._ta_lib.VAR(arrClose, 5, 1)
self.chartData_["adx"] = ta._ta_lib.ADX(arrHigh, arrLow, arrClose, 14)
self.chartData_["plusDI"] = ta._ta_lib.PLUS_DI(arrHigh, arrLow, arrClose, 14)
self.chartData_["plusDM"] = ta._ta_lib.PLUS_DM(arrHigh, arrLow, 14)
self.chartData_["atr"] = ta._ta_lib.ATR(arrHigh, arrLow, arrClose, 30)
사실 이 프로그램의 핵심 기능 보조 지표 계산 calcIndicator 가 이 클래스의 핵심입니다.
기술지표는 시가, 고가, 저가, 종가를 특정 목적에 맞게 계산식에 의해 도출된 값들입니다.
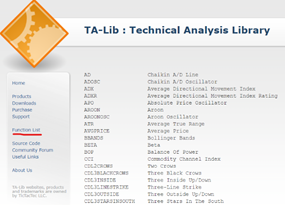
보통 추세, 지금 주식 가격이 계산상 적정 범위인가, 과 매수 매도 구간인가 판단하는데 도움을 주는 툴이며 인터넷 웹이나, hts 에 아래와 같이 여러 지표들을 보여주고 있습니다.

calcIndicator 함수 보시면 이 기술지표 데이터를 TaLib라는 라이브러리를 사용하여 계산 결과값만 받아왔습니다.
물론 원하는 기술지표를 직접 계산하시어도 문제없습니다만, 그 경우 결과 값이 정확한지 엑셀에 수식으로 구현해서 그 값과 같은 값이 나오는지 체크해서 써야 합니다만, 프로그램이 복잡해지는 문제가 발생됩니다.
그리고 이런 공개된 라이브러리에 계산 값이 다르거나 버그 나면, 전세계 사람들이 달려들어 수정하기 때문에 굳이 안 믿고 안 쓸 이유가 없다고 생각합니다.
TaLib 에 대해서는 https://ta-lib.org/ 홈페이지에 자세한 설명이 나와있고, 자세하건 오른쪽 홈페이지의 function list를 확인해서 원하는 기술지표 함수를 체크해서 사용하시는 게 좋습니다.
'재테크 > 주식 알람 시스템 만들기' 카테고리의 다른 글
| 5. 주식 차트 그리기 (0) | 2020.11.08 |
|---|---|
| 4-1 주식 데이터 저장 (sqlite) (0) | 2020.11.08 |
| 4. 주식 데이터 저장 (sqlite) (0) | 2020.11.07 |
| 2. 주식데이터 가지고 오기 (0) | 2020.11.07 |
| 1. 프로그램 설계 (0) | 2020.11.07 |