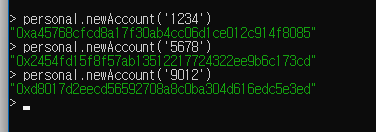
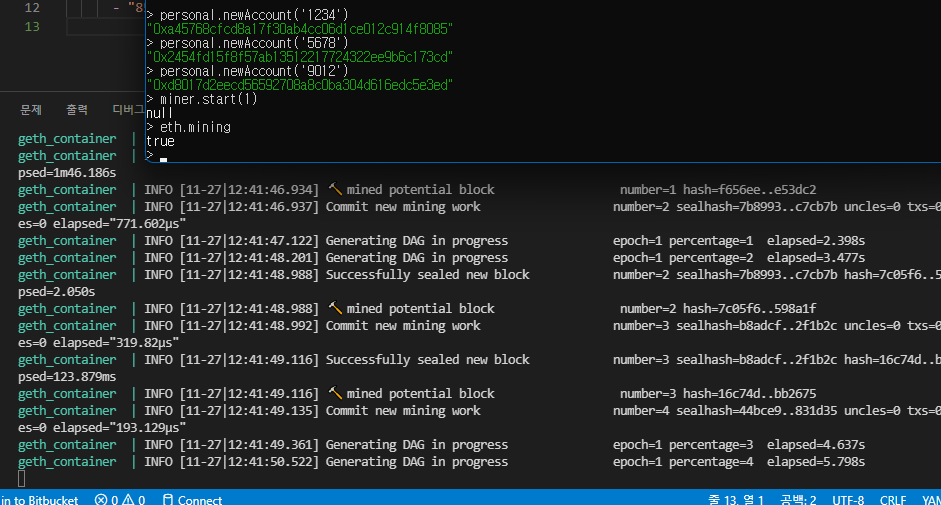
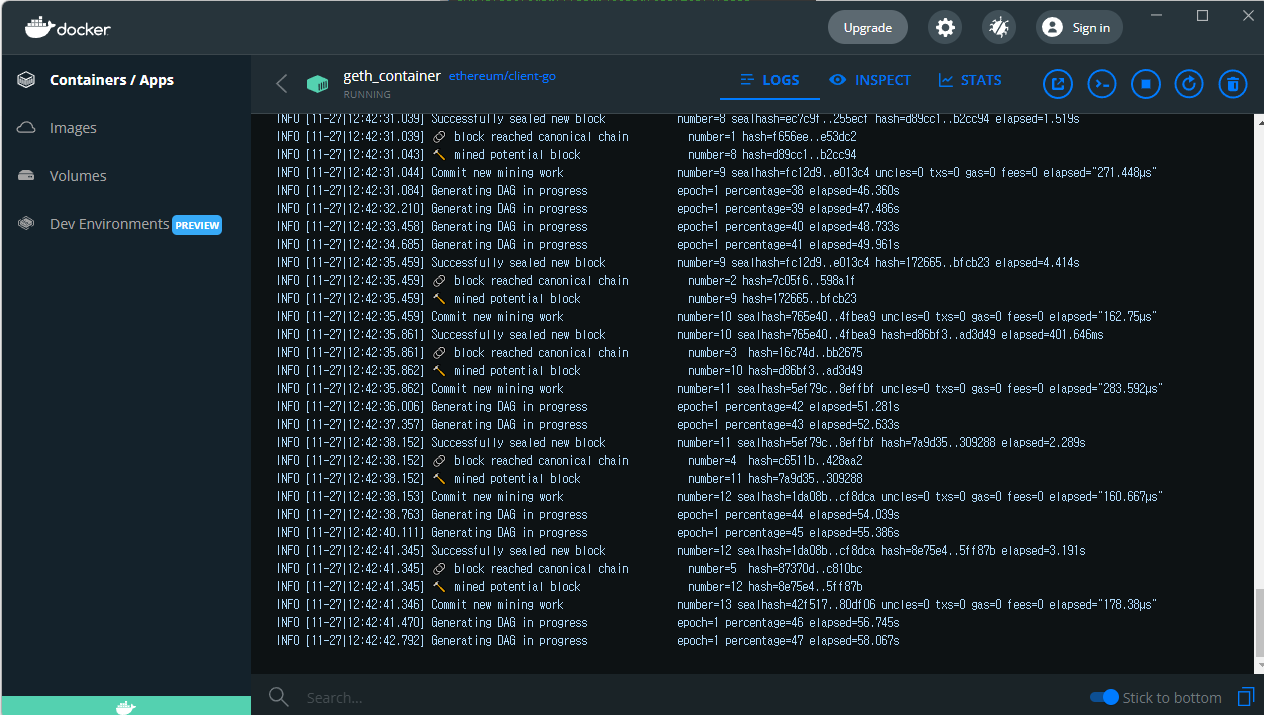
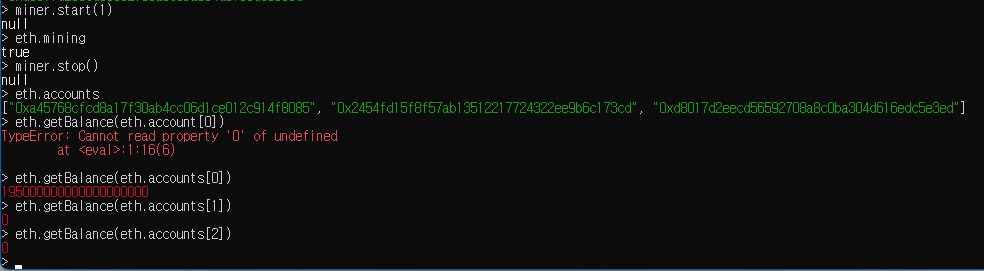
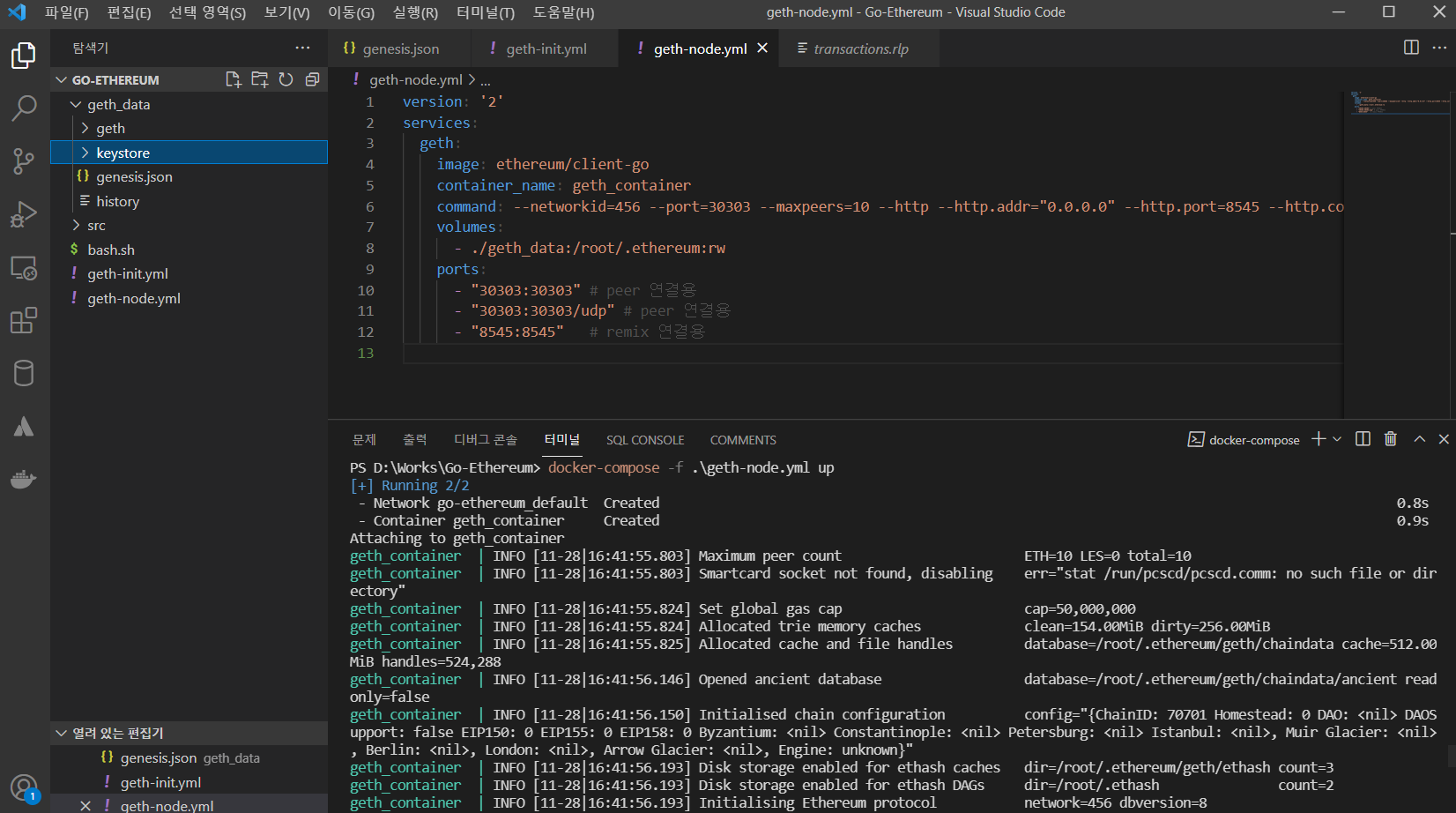
peer 연결에 사용할 listen port 로 30303 을 사용하고 (그래서 ports: 로 30303을 뚫었습니다. 8545는 웹에 연결할건데 이건 나중에 보죠),
다른 여러 예제들 보면 --rpc 옵션을 지정하게 되어 있는데,
최근 버전에는 rpc 옵션이 삭제되서 이대로 사용하면, 도커가 실행이 안됩니다.
rpc 옵션에 대해서는 http 로 대체 되었는데, 옵션 내용은 아래와 같습니다.
추가로 http.addr=0.0.0.0 으로 지정했는데, 도커에서 저렇게 해줘야 host(윈도OS)에서 localhost 에 접속이 가능합니다.
API AND CONSOLE OPTIONS: --ipcdisable Disable the IPC-RPC server --ipcpath value Filename for IPC socket/pipe within the datadir (explicit paths escape it) --http Enable the HTTP-RPC server --http.addr value HTTP-RPC server listening interface (default: "localhost") --http.port value HTTP-RPC server listening port (default: 8545) --http.api value API's offered over the HTTP-RPC interface --http.rpcprefix value HTTP path path prefix on which JSON-RPC is served. Use '/' to serve on all paths. --http.corsdomain value Comma separated list of domains from which to accept cross origin requests (browser enforced) --http.vhosts value Comma separated list of virtual hostnames from which to accept requests (server enforced). Accepts '*' wildcard. (default: "localhost") --ws Enable the WS-RPC server --ws.addr value WS-RPC server listening interface (default: "localhost") --ws.port value WS-RPC server listening port (default: 8546) --ws.api value API's offered over the WS-RPC interface --ws.rpcprefix value HTTP path prefix on which JSON-RPC is served. Use '/' to serve on all paths. --ws.origins value Origins from which to accept websockets requests --graphql Enable GraphQL on the HTTP-RPC server. Note that GraphQL can only be started if an HTTP server is started as well. --graphql.corsdomain value Comma separated list of domains from which to accept cross origin requests (browser enforced) --graphql.vhosts value Comma separated list of virtual hostnames from which to accept requests (server enforced). Accepts '*' wildcard. (default: "localhost") --rpc.gascap value Sets a cap on gas that can be used in eth_call/estimateGas (0=infinite) (default: 50000000) --rpc.evmtimeout value Sets a timeout used for eth_call (0=infinite) (default: 5s) --rpc.txfeecap value Sets a cap on transaction fee (in ether) that can be sent via the RPC APIs (0 = no cap) (default: 1) --rpc.allow-unprotected-txs Allow for unprotected (non EIP155 signed) transactions to be submitted via RPC --jspath loadScript JavaScript root path for loadScript (default: ".") --exec value Execute JavaScript statement --preload value Comma separated list of JavaScript files to preload into the console
암호화패 문제 뿐만아니라, 경제는 어려운데 주식이나 부동산은 왜 오르는지 잘 설명한 다큐멘터리입니다.
어쨋든 이걸 질러야 하나 말아야 하나 고민하다가 산 그래픽 카드
1,2달은 돌려야 본전은 뽑을꺼 같아서 집 PC로 채굴을 했습니다.
자료가 여기저기 파편화 되어있는걸 찾으면서 해봤습니다.
처음 해보시는 분들에겐 좋은 가이드가 되길 바랍니다.
1. driver 준비
암호화폐난으로 NVIDIA에선 드라이버에 채굴 lock 을 걸었습니다. 채굴 프로그램이 돈다고 감지되는 순간, 채굴 효율을 절반으로 떨어트립니다. (원래 0.0001 btc 캔다면, 이걸 의도적으로 0.00005 btc 캐도록 합니다)
그런데, 실수인거 같은데(지금 공식 홈페이지엔 없습니다), 이 lock이 해제된 드라이버가 잠깐 나왔습니다.
470.05 버젼인데 이 드라이버를 설치 하셔야 100% 성능이 나옵니다.
구글에서 rtx 3060 mining driver 470.05 download 라고 검색하는걸로 설치 하시기 바랍니다.
그리고 참고로 그래픽 카드 hdmi 가 꼽혀 있어야 100% 성능 나옵니다. 펌웨어 설정인지 몰라도, gpu 100% 쓰고 있는데 모니터 출력이 없으면 무족건 해시를 반으로 다운 시키더군요. 굳이 끼고 싶지 않으면 시중에 판매되는 hdmi 더미를 구입해서 끼는것도 방법입니다.
2. gpu 오버 클럭 프로그램 (msi 의 경우 애프터 버너 프로그램)
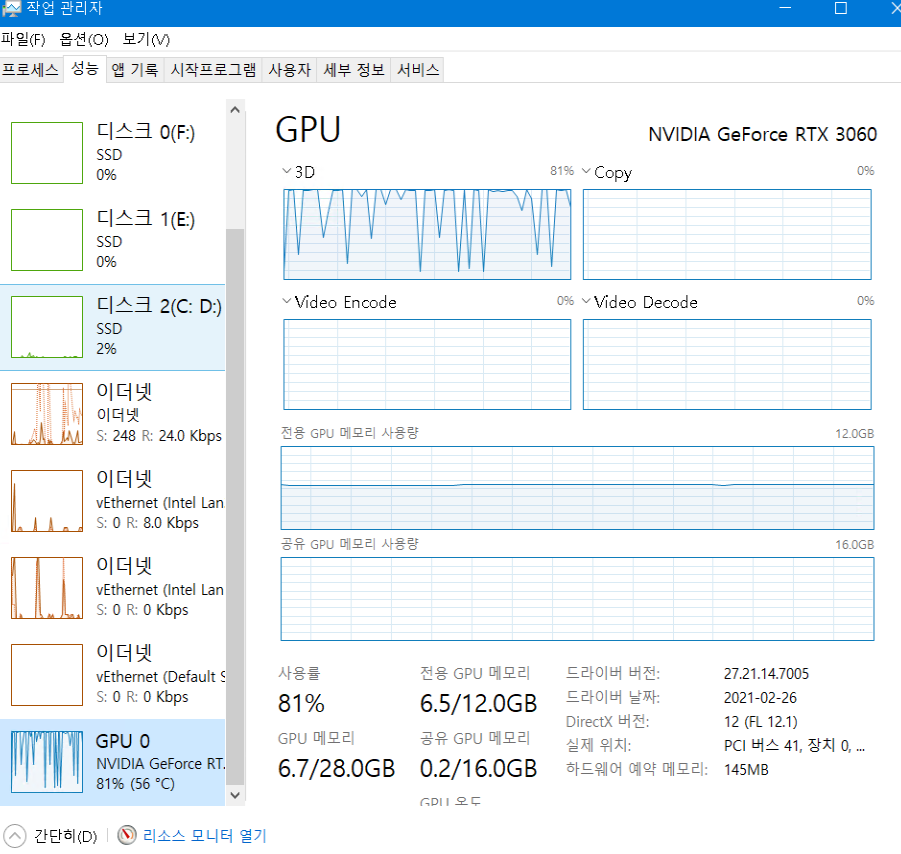
gpu 를 100%, 120% 쓸 필요 없습니다. 어차피 아래와 같이 프로그램은 GPU를 100% 씁니다.
대신 전성비라고 해서 전기쓰는 효율 대비 gpu 효율을 잘 뽑아야 합니다.
무슨 말이냐면 파워를 65%만 공급해도 채굴량이 비슷하다는 것입니다 !!!
24시간 내내 일하는거 100%로 돌리면 전기세도 많이 나오고, gpu도 금방 망가질테니 적절한 전압을 조절해야 하는게 좋습니다
제 그래픽카드는 MSI라 애프터 버너 프로그램 썻는데, 각 제조사마다 오버클럭 관련 프로그램 검색해서 설정하는게 좋습니다.
3-a. 안정적인 비트코인 채굴하기.
비트코인은 솔직히 망할거 같진 않습니다.
허상이네 아니네 그런 논쟁을 하려면 이미 2017,18년에 망했어야 했다고 봅니다.
가장 사람들에게 인식이 각인된 비트코인 그리고 모든 알트코인과도 환전이 가능하기 때문에 많이들 비트코인을 채굴합니다.
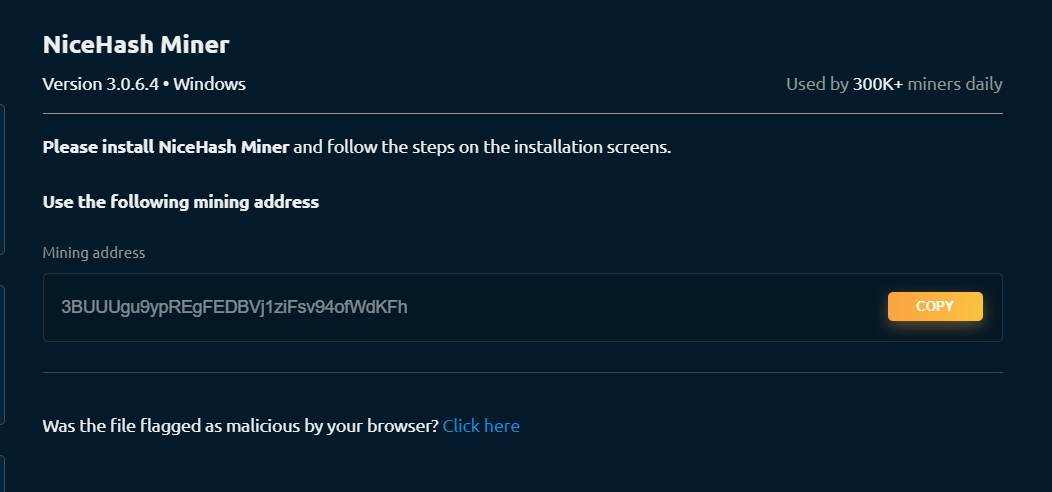
문제는 비트코인은 전용 채굴 장비로 해야 어느정도 나오는데, 일반 사람들이 그럴 수 없으므로 일종의 mining pool 에 여러 pc들이 node 연결하여 hash power를 갖고 옵니다.