이전엔 잘 됬다가 윈도우 11업데이트 이후 원격 접속이 안되면 3가지를 확인해 봐야 합니다.
1. 백신에 AhnLab Safe Transaction 이 있는지 확인 해 보고 환경설정에서
아래와 같이 원격 접속 차단이 걸려 있는지 확인

2. 전원 옵션이 최대성능이 아닌지 확인
이게 자동으로 균형 조정으로 설정이 되기도 하는데 이럴땐 설정 변경 들어가서 절전모드를 모두 무효화 시켜 줍니다.
3. 이래도 안되는 경우가 있는데, 아래에서와 같이 원격접속에 UDP를 끄면 해결이 될수 있다고 합니다.
https://hothardware.com/news/windows-11-22h2-breaking-remote-desktop-connections-workaround
Windows 11 22H2 Is Breaking Remote Desktop Connections, Here's A Temporary Workaround
According to user reports, the most recent 22H2 update to Windows 11 seems to be breaking remote desktop features, but users have found some potential fixes.
hothardware.com
윈도우 실행 -> 그룹 정책 편집
아래와 같은 창에서 컴퓨터구성 -> 관리 템플릿 -> Windows 구성요 -> 터미널 서비스 -> 원격 테스크톱 연결 클라이언트
-> Turn Off UDP on Client 사용안함 -> 리붓
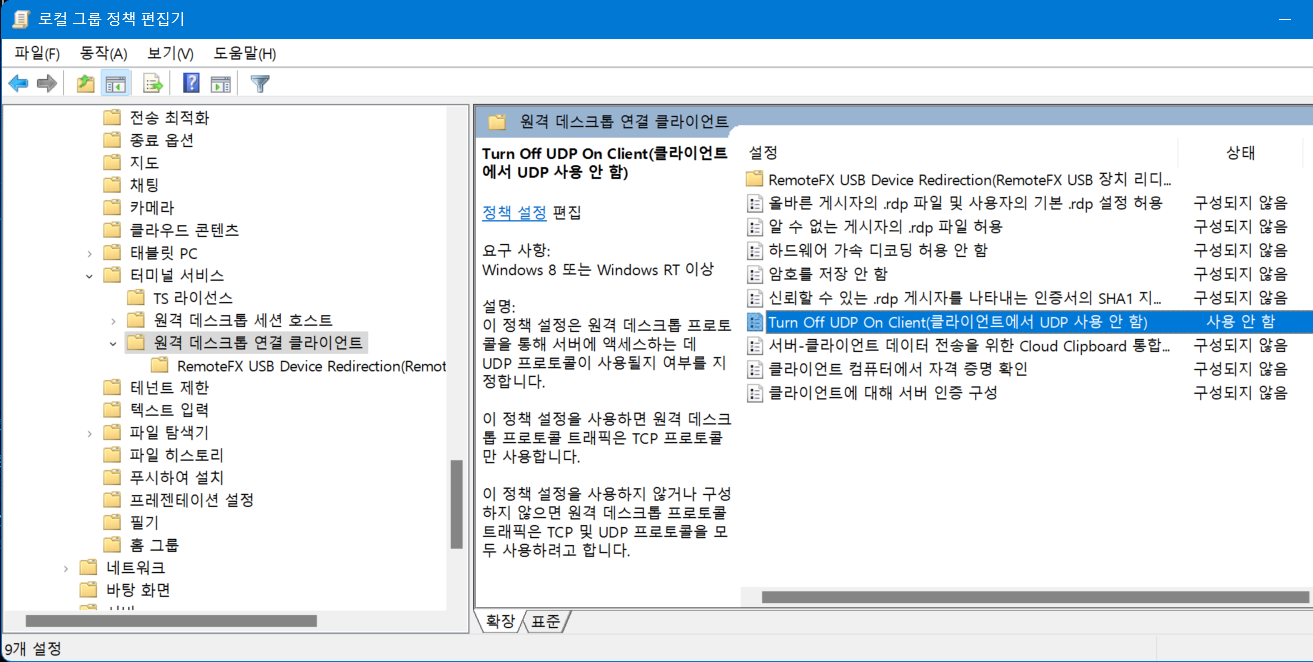
혹시나 이래도 접속이 안될수 있기 때문에 인트라망이 아니라면
구글 원격접속도 같이 설치해서 만약에 윈도 원격접속으로 접속이 안되면 구글 원격 접속으로 들어가서 리붓 할수 있도록 준비하는게 좋습니다.
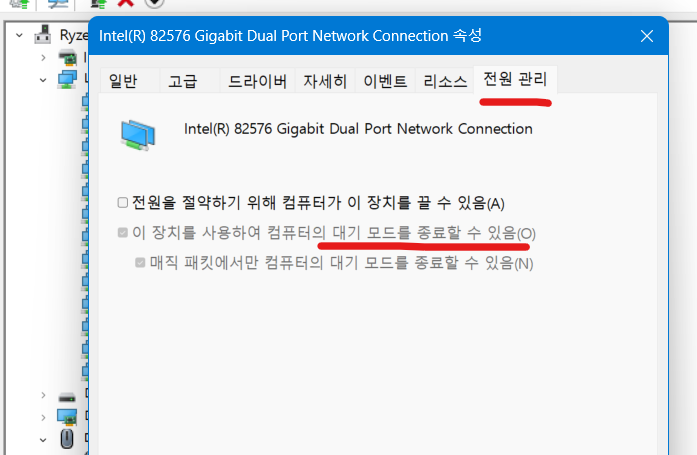
4. 절전모드 해제 들어가는 하드웨어가 있는지 검색
| cmd 로 들어가서 아래의 명령어를 쳐줍니다. powercfg -devicequery wake_armed |
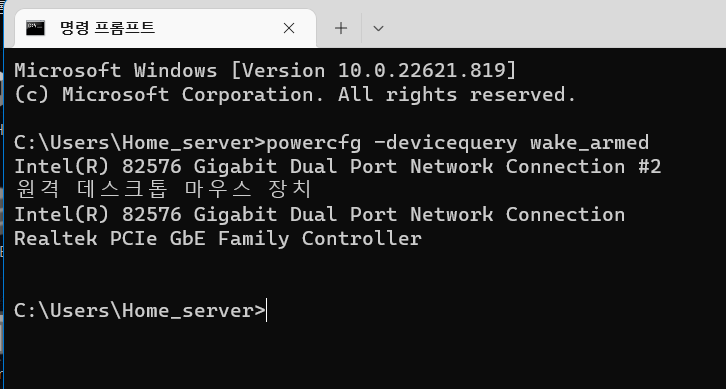
위의 리스트가 나오는데, 기억해 둡시다.
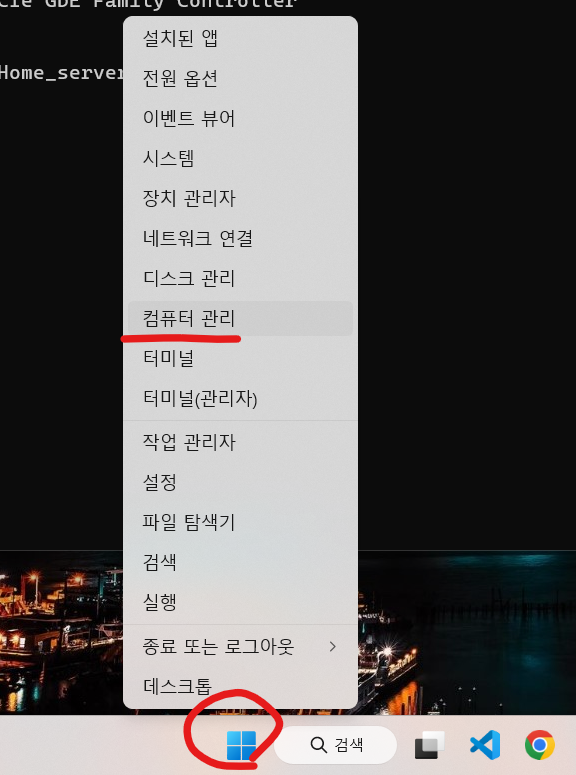
마우스로 윈도우 버튼에서 오른쪽 버튼 누르면 여러 메뉴들이 뜨는데, 거기서 "컴퓨터 관리" 를 클릭합니다.
아까 cmd 에서 뜬 리스트를 장치 관리자내에서 찾아주고 항목을 클릭 합니다.
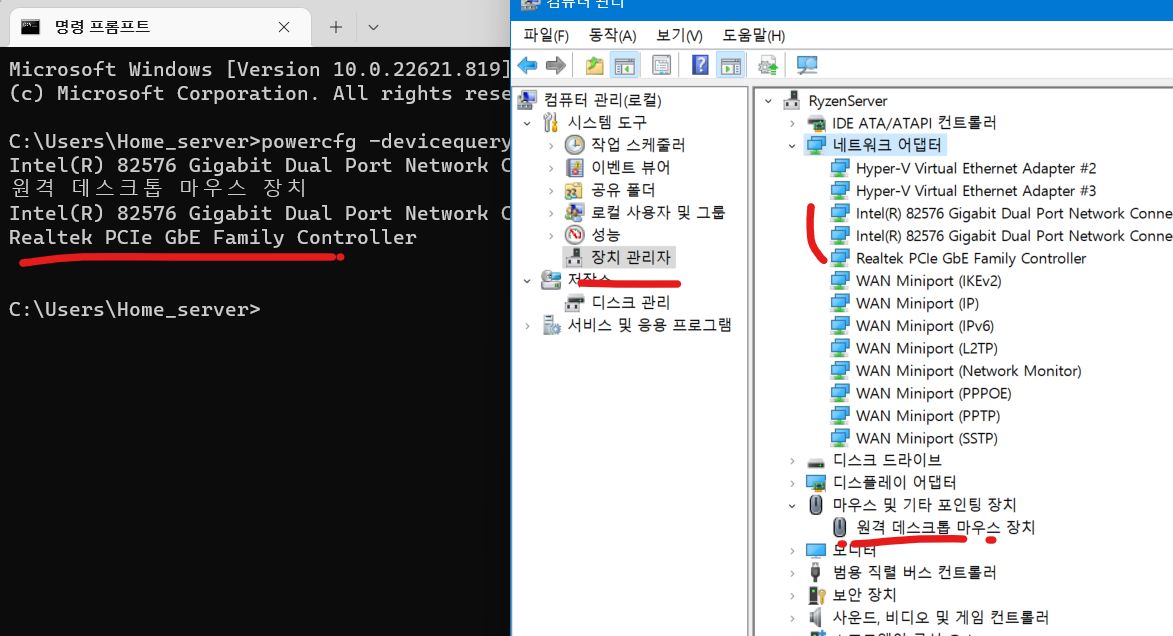
전원 관리 탭에 들어가서 아래와 같이 항목을 모두 해제 합니다.